Різниця між масивом та пов'язаним списком

Зміст
- Порівняльна діаграма
- Визначення масиву
- Давайте розглянемо деякі поняття, які слід пам’ятати про масиви:
- Операції, що виконуються на масивах:
- Приклад
- Визначення пов'язаного списку
- Операції, що виконуються у зв’язаному списку:
- Приклад
- Висновок
Основна різниця між Масив і Пов'язаний список щодо їх структури. Масиви є на основі індексу структура даних, де кожен елемент пов'язаний з індексом. З іншого боку, пов'язаний список покладається на посилання де кожен вузол складається з даних та посилань на попередній та наступний елемент.
В основному масив - це набір подібних об'єктів даних, що зберігаються в послідовних місцях пам'яті під загальним заголовком або ім'ям змінної.
Хоча пов'язаний список - це структура даних, яка містить послідовність елементів, де кожен елемент пов'язаний зі своїм наступним елементом. У елементі пов'язаного списку є два поля. Одне - це поле Дані, а інше - поле зв’язку. Поле даних містить фактичне значення, яке потрібно зберігати та обробляти. Крім того, поле посилання містить адресу наступного елемента даних у зв'язаному списку. Адреса, що використовується для доступу до певного вузла, відома як покажчик.
Ще одна істотна відмінність між масивом і пов'язаним списком полягає в тому, що масив має фіксований розмір і його потрібно оголосити попередньо, але пов'язаний список не обмежується розміром, а розгортається та стискається під час виконання.
- Порівняльна діаграма
- Визначення
- Ключові відмінності
- Висновок
Порівняльна діаграма
| Основа для порівняння | Масив | Пов'язаний список |
|---|---|---|
| Основні | Це послідовний набір фіксованої кількості елементів даних. | Це впорядкований набір, що містить змінну кількість елементів даних. |
| Розмір | Вказується під час декларації. | Не потрібно вказувати; зростати і скорочуватися під час виконання. |
| Розподіл зберігання | Місце розташування елементів розподіляється під час компіляції. | Позиція елемента призначається під час виконання. |
| Порядок елементів | Зберігається послідовно | Зберігається випадковим чином |
| Доступ до елемента | Прямий або випадковий доступ, тобто вкажіть індекс масиву чи індекс. | Послідовний доступ, тобто прохід, починаючи з першого вузла в списку вказівником. |
| Вставлення та видалення елемента | Повільно, оскільки потрібне зміщення. | Легше, швидше та ефективніше. |
| Пошук | Двійковий пошук та лінійний пошук | лінійний пошук |
| Потрібна пам'ять | менше | Більше |
| Використання пам'яті | Неефективний | Ефективний |
Визначення масиву
Масив визначається як набір певної кількості однорідних елементів або елементів даних. Це означає, що масив може містити лише один тип даних, або всі цілі числа, всі числа з плаваючою комою або всі символи. Декларація масиву така:
int a;
Де int вказує тип даних або тип елементів зберігає масив елементів. "A" - це ім'я масиву, і число, вказане всередині квадратних дужок, - це кількість елементів, які масив може зберігати, це також називається розміром або довжиною масиву.
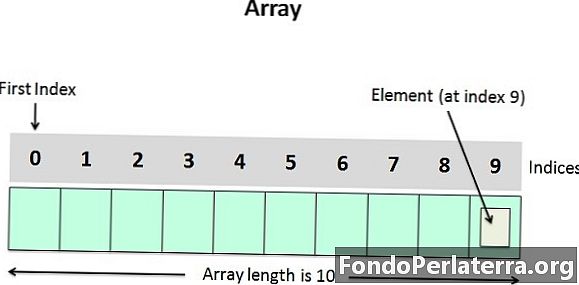
Давайте розглянемо деякі поняття, які слід пам’ятати про масиви:
- Доступ до окремих елементів масиву можна отримати шляхом опису імені масиву, а потім індексу або індексу (визначення місця розташування елемента в масиві) всередині квадратних дужок. Наприклад, щоб отримати 5-й елемент масиву, нам потрібно написати операцію a.
- У будь-якому випадку елементи масиву будуть зберігатися в послідовній пам'яті.
- Найперший елемент масиву має індекс нуль. Це означає, що перший і останній елемент будуть вказані як a, так і відповідно.
- Кількість елементів, які можуть бути збережені в масиві, тобто розмір масиву або його довжина задається наступним рівнянням:
(верхня межа - нижня межа) + 1
Для вищевказаного масиву було б (9-0) + 1 = 10. Де 0 - нижня межа масиву, а 9 - верхня межа масиву. - Масиви можна читати або записувати через цикл. Якщо ми читаємо одновимірний масив, йому потрібен один цикл для читання, а інший - для запису (ing) масиву, наприклад:
а. Для читання масиву
для (i = 0; i <= 9; i ++)
{scanf ("% d", & a); }
б. Для запису масиву
для (i = 0; i <= 9; i ++)
{f ("% d", а); } - У випадку двовимірного масиву знадобиться дві петлі, і аналогічно n-мірному масиву знадобиться n циклів.
Операції, що виконуються на масивах:
- Створення масиву
- Проходження масиву
- Вставлення нових елементів
- Видалення необхідних елементів.
- Модифікація елемента.
- Об’єднання масивів
Приклад
Наступна програма ілюструє читання та запис масиву.
#включати
#включати
недійсний головний ()
{
int a, i;
f ("Введіть масив");
для (i = 0; i <= 9; i ++)
{
scanf ("% d", & a);
}
f ("Введіть масив");
для (i = 0; i <= 9; i ++)
{
f ("% d n", a);
}
getch ();
}
Визначення пов'язаного списку
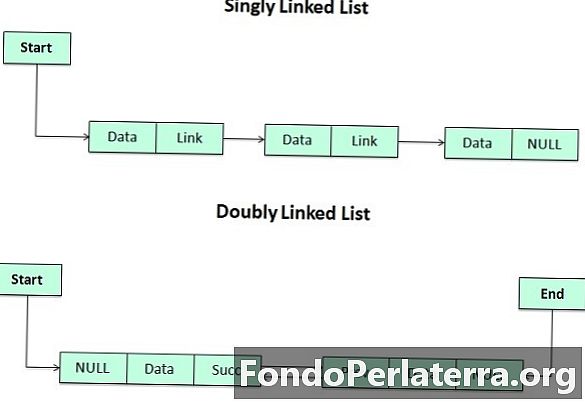
Зв'язаний список - це певний перелік деяких елементів даних, пов'язаних один з одним. У цьому кожен елемент вказує на наступний елемент, який представляє логічне впорядкування. Кожен елемент називається вузлом, який має дві частини.
Частина INFO, яка зберігає інформацію, і POINTER, який вказує на наступний елемент. Як ви знаєте, для зберігання адреси ми маємо унікальну структуру даних у C, що називається покажчиками. Отже, друге поле списку повинно бути типом вказівника.
Типи пов'язаних списків - це одиночно пов'язаний список, подвійно пов'язаний список, круговий зв'язаний список, круговий подвійний зв'язаний список.
Операції, що виконуються у зв’язаному списку:
- Створення
- Проїзд
- Введення
- Видалення
- Пошук
- Сполучення
- Дисплей
Приклад
Наступний фрагмент ілюструє створення пов'язаного списку:
структурний вузол
{
int num;
штрих вузол * поруч;
}
старт = NULL;
void create ()
{
typedef struct node NODE;
NODE * p, * q;
вибір вибору;
перший = NULL;
робити
{
p = (NODE *) malloc (sizeof (NODE));
f ("Введіть елемент даних n");
scanf ("% d", & p -> число);
якщо (p == NULL)
{
q = початок;
while (q -> next! = NULL)
{q = q -> далі
}
p -> next = q -> наступний;
q -> = p;
}
ще
{
p -> наступний = початок;
старт = р;
}
f ("Ви хочете продовжити (введіть y чи n)? n");
scanf ("% c", & вибір);
}
while ((вибір == y) || (вибір == Y));
}
- Масив - структура даних містить набір елементів подібних типів даних, тоді як список пов'язаних даних вважається непомітною структурою даних, містить колекцію не упорядкованих пов'язаних елементів, відомих як вузли.
- У масиві елементи належать до індексів, тобто, якщо ви хочете потрапити в четвертий елемент, ви повинні написати ім'я змінної з її індексом або розташуванням у квадратній дужці.
Однак у пов'язаному списку вам потрібно починати з голови і проробляти свій шлях до тих пір, поки не дістанетесь до четвертого елемента. - Хоча доступ до масиву елементів є швидким, тоді як список пов'язаних ліній займає лінійний час, тому він є дещо повільнішим.
- Такі операції, як вставка та видалення в масивах, займають багато часу. З іншого боку, виконання цих операцій у пов'язаних списках швидко.
- Масиви мають фіксований розмір. Навпаки, пов'язані списки є динамічними та гнучкими і можуть розширювати та скорочувати його розмір.
- У масиві пам'ять призначається під час компіляції, тоді як у списку пов'язаних файлів вона виділяється під час виконання або під час виконання.
- Елементи зберігаються послідовно у масивах, тоді як вони зберігаються випадковим чином у пов'язаних списках.
- Потреба в пам'яті менша за рахунок фактичних даних, що зберігаються в індексі в масиві. На противагу, у пов'язаних списках потребує більше пам'яті через зберігання додаткових наступних та попередніх посилальних елементів.
- Крім того, використання масиву не є ефективним у масиві. І навпаки, використання масиву пам'яті ефективно в масиві.
Висновок
Списки масивів і пов'язаних типів - це типи структур даних, що відрізняються за своєю структурою, методами доступу та маніпулювання, потребою в пам'яті та використанням. І мають особливу перевагу та недолік щодо його реалізації. Отже, будь-який може бути використаний відповідно до потреби.





